Introduction
I was working on a project recently that required handling large spikes of traffic using Azure Functions and ran into a few challenges scaling connections to a shared Redis instance.
The application contained a set of 3 Azure Functions, two of which had HTTP bindings, and one bound to a Service Bus message queue. Two of the functions depend on Redis, an open source, in-memory data store.
This post focuses on Redis, but the same principles apply to other dependencies that may hold sessions. This includes databases, caches / KV stores, and even APIs accessed over HTTP. The consistent problem is a dependency that has some sort of session state.
Initial Implementation
The function implementation was quite simple, each one ran some checks and wrote to Redis. I’ll use this simplified version of our functions going forward:
export default async function (
context: Context,
req: HttpRequest
): Promise<void> {
// Construct Redis service instance
const redis = await RedisService.create(context);
try {
// ... Business Logic
// Write to Redis
redis.set("some-key", "some-value");
} catch (e) {
context.log.error("Could not handle request", e);
throw e;
}
}The business logic here isn’t important. What is important is how the service is implemented.
I am writing several functions using a shared Redis service implementation, so I wrapped the node-redis client in a singleton. This ensures that a single instance of the service is created. Of course, this pattern doesn’t have much of an impact in serverless architecture. Still, it writes well for this use case.
export default class RedisService {
#client: RedisClientType;
#context: Context;
constructor(context: Context, client: RedisClientType) {
this.#context = context;
this.#client = client;
}
static async create(context: Context): Promise<RedisService> {
const client = createClient({
url: process.env.REDIS_HOST,
password: process.env.REDIS_ACCESS_KEY,
});
await client.connect();
return new RedisService(context, client);
}
// This is an example, there are many methods on this service
async set(key: string, value: string): Promise<void> {
await this.#client.set(key, value);
}
}As you can see, this implementation uses a static async factory to construct an instance. This allows us to await redis.connect(), a method that establishes a connection with Redis and ensures the service is ready to use.
With this in place, we started running load tests. The tests simulated traffic for approximately 10,000 users.
First Problem: Max Concurrent Sessions
Azure Cache for Redis is priced based on a few factors. One of them is the Maximum Connection Limit. This is a hard limit enforced by Azure and describes the number of active, open sessions that clients have with the Redis instance. If the number of sessions grows beyond this point, connecting clients will be unable to establish a new session.
The tier we were using was the lowest tier, allowing 250 max connections. Up-to-date pricing can be found here.
In the first test, we saw a large number of connection timeout errors. The only reported exception was a timeout in the Redis client.
Exception while executing function: Functions.function-name-redacted Result: Failure
Exception: Connection timeout
Stack: Error: Connection timeout
at TLSSocket.<anonymous> (/home/site/wwwroot/dist/node_modules/@redis/client/dist/lib/client/socket.js:178:124)
at Object.onceWrapper (node:events:627:28)
at TLSSocket.emit (node:events:513:28)
at Socket._onTimeout (node:net:570:8)
at listOnTimeout (node:internal/timers:569:17)
at process.processTimers (node:internal/timers:512:7)Based on the lack of any logs from our custom code, it was easy to determine that this was being thrown during the factory initialization of our Redis Service. That means it must be failing on client.connect() because that is the only code that would result in I/O.
Looking Azure’s Insights for the Redis cache, it was easy to spot the issue. We were reaching that 250 connection limit.
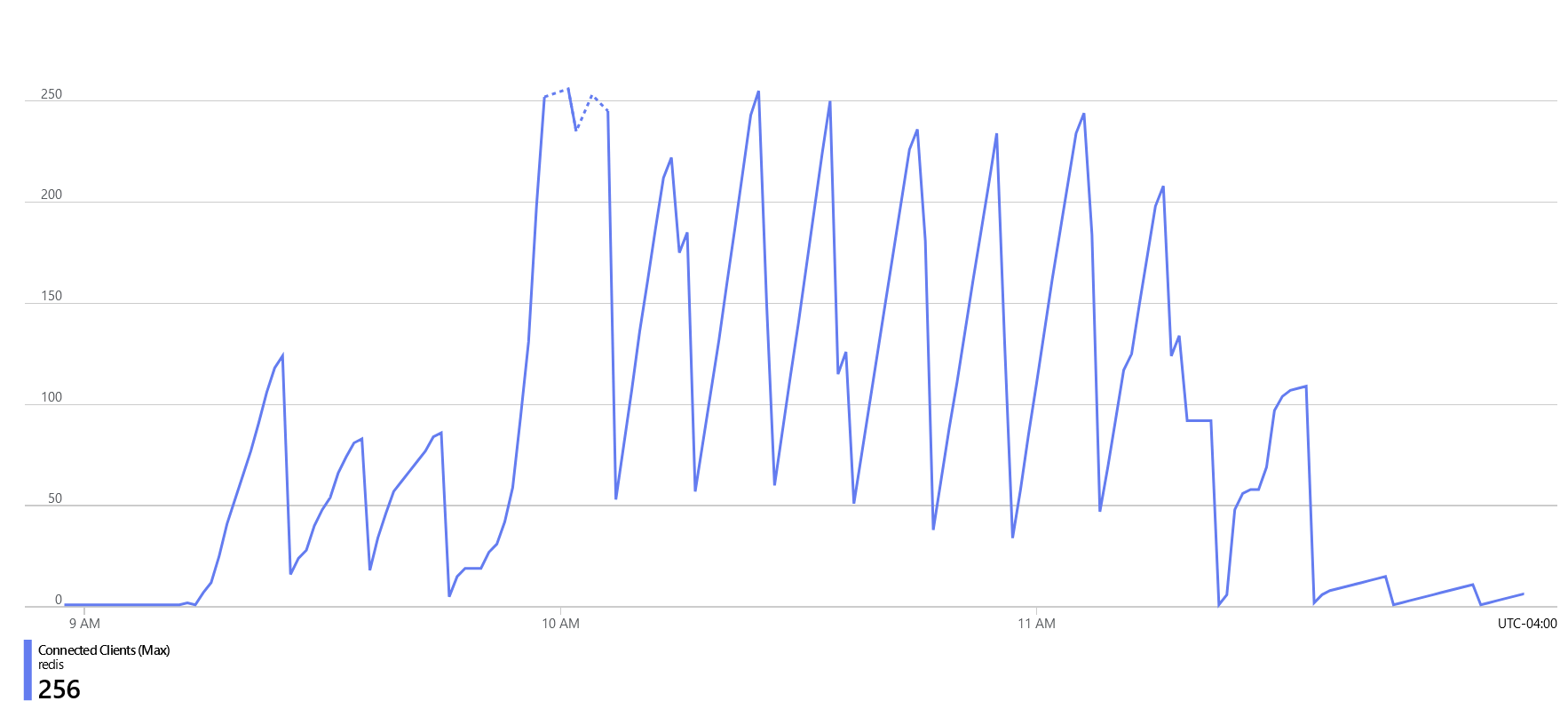
Some readers may have noticed the issue - the initial implementation fails to close the Redis client. I assumed that when the invocation finished, the Node process would be terminated, and the Redis client would be cleaned up. However, this is not the case with Azure Functions. Azure Function instances are not automatically cleaned up after each invocation and can be reused for an unpredictable amount of time.
As the application scaled to 200 instances during bursts of traffic, each was holding onto its Redis sessions between executions. Consequently, if each invocation created a new Redis client connection without explicitly disposing it, 200 instances exdcuting in quick succession could quickly reach the 250 connection limit.
Luckily, we can control the maximum number of instances using the Scale Out settings in the Azure Function App configuration panel.
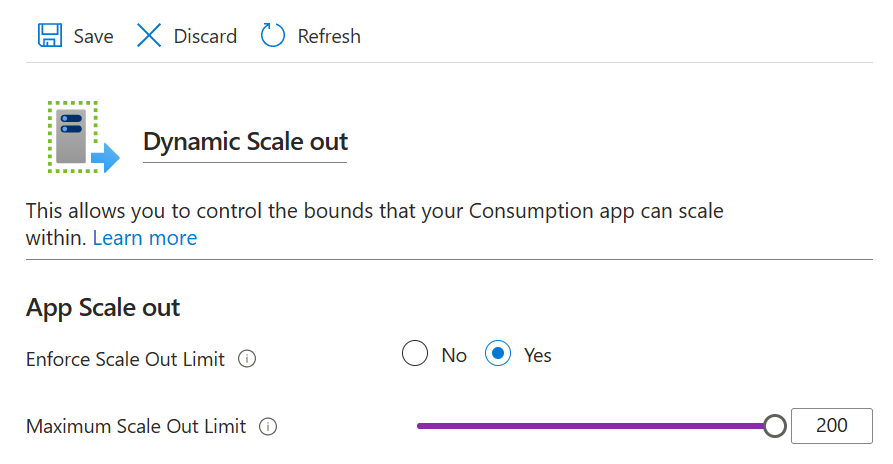
One solution would be to reduce the maximum number of instances in the Scale Out settings. This would create room enough instances but could prevent them from exceeding the connection limit. Another option is to upgrade the Redis tier to increase the maximum connection limit, but this comes at a higher cost.
If we decide to cache instances, we must ensure that the timeouts in each system align. We need a mechanism to handle potential issues with the sessions (timeouts, interruptions, etc.) by recreating it if necessary. While Redis connections don’t time out by default, we can’t assume that a Redis session created at one point is indefinitely reusable.
There is one more simple way to deal with this. Just close the client! If we create and close the client inside our function, then it won’t be reused across sessions. Let’s refactor our application to close Redis instances after our work is done.
We’ll add a quit method to our service:
export default class RedisService {
// ...
+ // Close the Redis session explicitly
+ async quit() : Promise<string> {
+ return this.#client.quit();
+ }
}Then call it in a finally clause in our function:
export default async function (
context: Context,
req: HttpRequest
): Promise<void> {
// Construct Redis service instance
const redis = await RedisService.create(context);
try {
// ... Business Logic
// Write to Redis
redis.set("some-key", "some-value");
} catch (e) {
context.log.error("Could not handle request", e);
throw e;
} finally {
// Close client
await redis.quit();
}
}Now, our functions will create a new client each invocation, and dispose of it. Disposing of this client will free up a spot for another client to be instantiated.
This should avoid creating more clients than we have function instances at any given moment. Since our Scale Out limit can be set to a maximum of 200, this should mean we never open 250 concurrent connections (assuming each function instance can only run one invocation at a time).
Next Problem: The Same Problem Again
With the new code in place, we ran a small test again. This time, we saw significantly fewer Redis Client Connections being created. However, we were still getting a large number of errors.
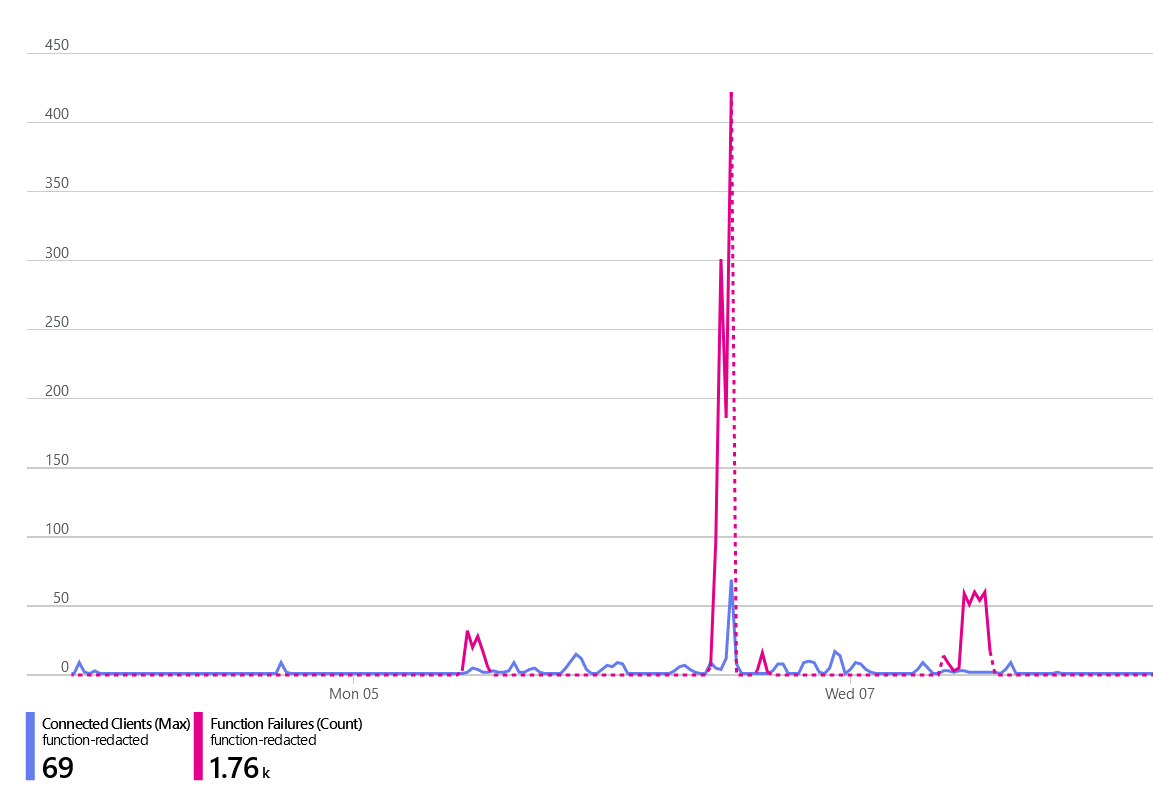
All of these timeouts once again originated from our constructor where we initialize the Redis client.
There were no real symptoms this time besides the exception. No spikes in connections, and even the Redis instance didn’t seem like it was utilized. I determined it was likely that the overhead of creating and disposing these instances is the cause. At the very least, it’s a small amount of overhead that could probably be improved upon.
So we’re back to reusing the Redis instance across invocations as being the next best bet. Sure enough, Azure’s documentation even recommends reusing clients. The recommendation is quite clear:
To avoid holding more connections than necessary, reuse client instances rather than creating new ones with each function invocation.
So we need to reuse the instances. But how can we do this without getting caught up worrying about specific timeouts and errors, number of instances, etc.
Our application had zero legitimate cases where the Redis client should throw an error. That means, in any case that Redis throws, the client has either timed out or something is terribly wrong (in which case, solutions here are futile).
This means we can simplify our logic for managing the session to a simple rule: recreate failing clients.
Now, we just remove our call to redis.quit() in our function implementations, and adjust our Redis service as follows:
// static helper to create a new client
const createRedisClient = async (): Promise<RedisClientType> => {
const client = createClient({
url: process.env.REDIS_HOST,
password: process.env.REDIS_ACCESS_KEY,
});
await client.connect();
return client;
};
export default class RedisService implements LoggerProvider {
static #_client = null;
#context: Context;
#client: RedisClientType;
constructor(context: Context, client: RedisClientType) {
this.#context = context;
this.#client = client;
}
static async create(context: Context): Promise<RedisService> {
// Return an instance of RedisService with a reference to the static client
return new RedisService(context, await RedisService.getClient(context));
}
static async getClient(context: Context): Promise<RedisClientType> {
// If we don't have a client yet, create one
RedisService.#_client =
RedisService.#_client || (await createRedisClient());
try {
// Ping the client (resets any command timeout)
await RedisService.#_client.ping();
// Ping successful, we can use this client
context.log("Reusing existing active client");
} catch (e) {
// Could not ping client - we should recreate it
context.log.warn("Stale client found - creating new client", e);
try {
// Close the existing client if we can
await RedisService.#_client.quit();
} catch (e) {
context.log.warn("Could not close stale client", e);
}
// Create a new client
RedisService.#_client = await createRedisClient();
context.log(
`Created new client ${await RedisService.#_client.clientId()}`
);
}
return RedisService.#_client;
}
async quit(): Promise<string> {
return this.#client.isOpen ? this.#client.quit() : "OK";
}
}Results
After these changes, the application was able to scale to 10,000 users, and between the two functions in the app with HTTP bindings, we were able to process more than 35,000 function invocations in just over 30min (~19req/s) with no errors.
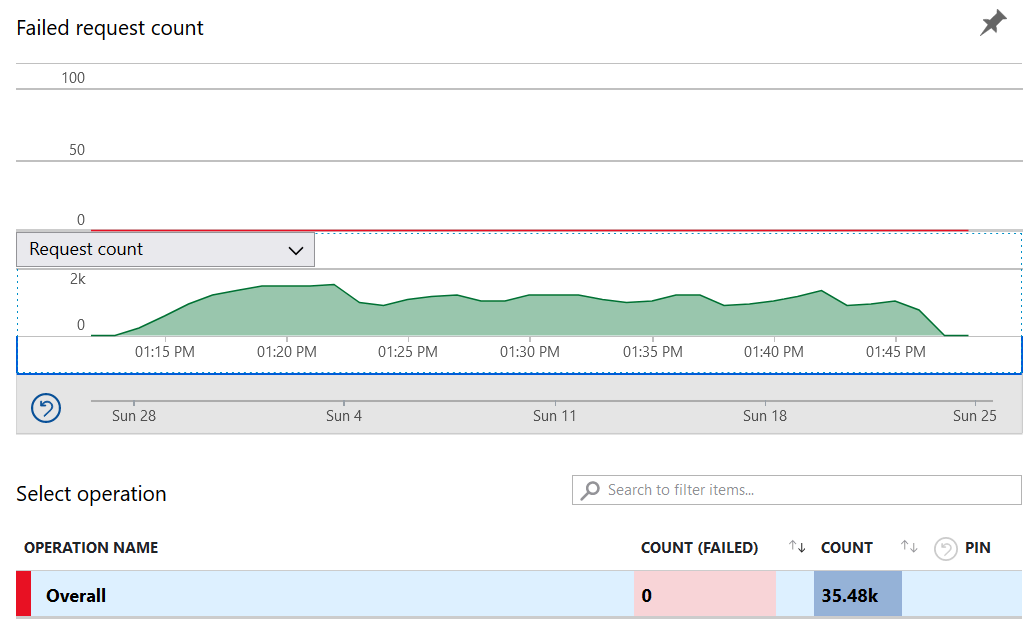
This could likely scale even further on its own and could be further improved with a higher Redis cache tier, a higher or unlimited Scale Out limit, and a few tweaks to the business logic to account for different data availability guarantees provided by a Redis Cluster.
References
Thank you to the writers of the following sources which were instrumental: